测试网节点教程系列 8:Farcaster


本系列之前的教程请见:https://forum.hammerplease.uk/t/topic/99
一不小心才发现自己已经停更了好几个月了 23333 有些惭愧,对不起自己早几个月前的雄心壮志。但不管怎么说,keep moving 吧。
这次给大家带来的是 farcast 的节点搭建教程。farcaster 如果还不知道的人需要了解和玩一下,这个项目现在已经很活跃+成熟。可以通过我的邀请链接加入:https://warpcast.com/~/invite-page/317724?id=b50abc3c
根据 TechCrunch 的报道,这个项目拿了 150M 的投资(非常豪华了),日活有 80k。
 Amanda Silberling
Amanda Silberling
Backers & Investors 可以见下面这篇文章的说明:
首先查看自己的服务器是否符合要求:
- 16 GB of RAM
- 4 CPU cores or vCPUs
- 140 GB of free storage
- A public IP address with ports 2282 - 2285 exposed
关于存储可能不止 140 GB 我还没同步完已经用了 138 GB。内存和 CPU 没有太大的问题。
我本想参考 xiaorun 的教程完成搭建的,但是发现中途出现了故障。但因为发生的太快所以我没有记录下来。
我会推荐直接使用官方的傻瓜教程直接安装:
curl -sSL https://download.thehubble.xyz/bootstrap.sh | bash本质上这个脚本也是利用了 docker 来启动了,所以需要提前在自己的机器上面安装好 docker。而安装 docker 的话我也推荐直接使用官方的傻瓜脚本:
curl -sSL https://get.docker.com | bash启动之后会有交互命令提示输入主网的 RPC 和 Optimism 的 RPC,我直接使用了 Alchemy,没有的话可以在这边注册:https://dashboard.alchemy.com/ 提供的免费额度已经完全足够日常使用了。
然后会要求输入 farcast 的 用户 ID ,这个在自己的 warpcast 点菜单 关于里面就可以获取到。
然后就可以看到日志提示在下载 snapshot。另外需要注意如果端口(2283)没有开通的话会报错重新再开始下载和解压操作,所以建议还是在有公网的机器上操作。
然后打开机器 ip 对应的 3000 端口就能看到 grafana 的监控已经在同步中:
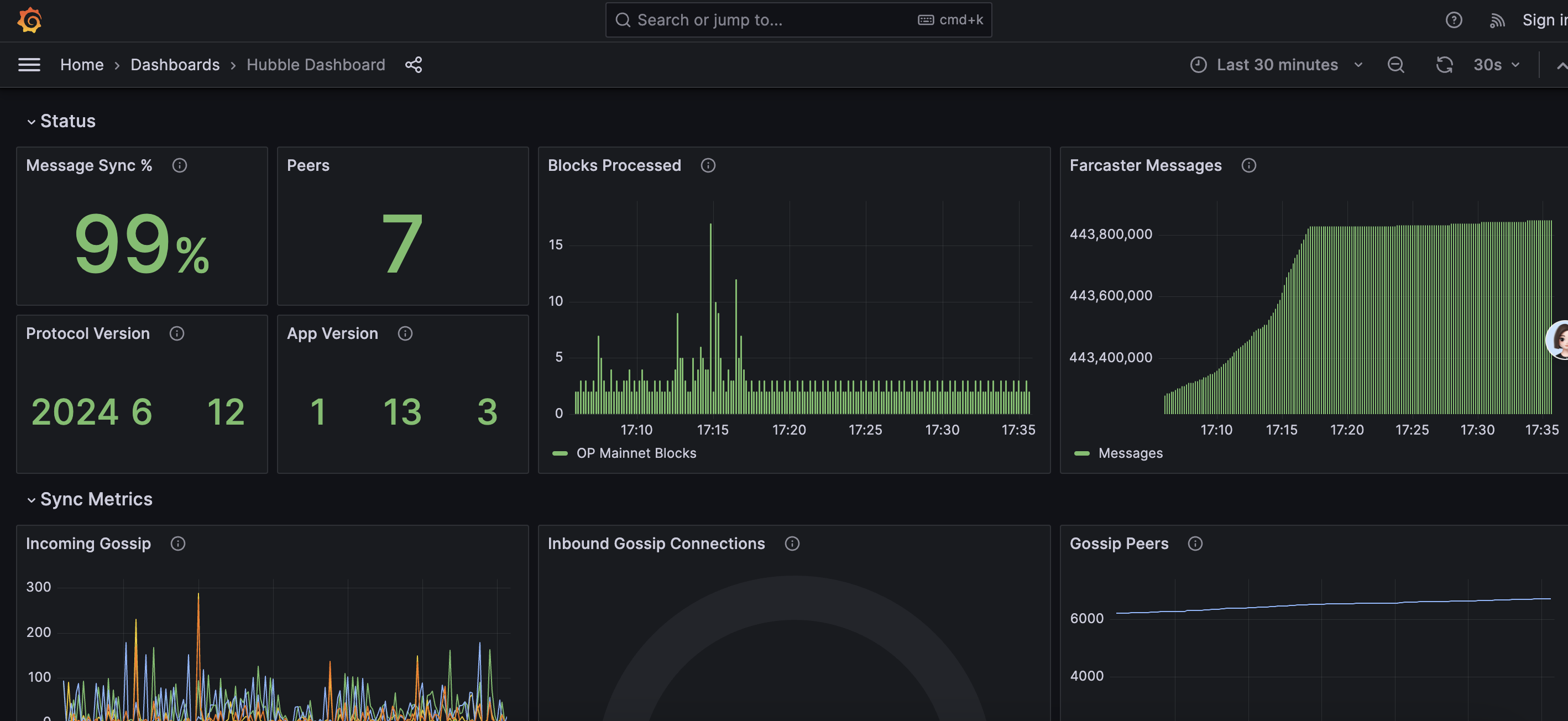
当前要到 446,xxxx 才能完成 sync,所以耐心等候就行。
到这里这个教程就完了。
2024.07.23 更新
今天发现 grafana 打不开了 没有指标数据 我一直以为可能是资源加载的问题 但实际上应该是 hubble 挂了一段时间了,查看日志是这样:
hubble-1 | {"message":"Err {\n error: HttpRequestError: HTTP request failed.\n \n Status: 403\n URL: https://eth-mainnet.g.alchemy.com/v2/xxxxxxxx\n Request body: {\"method\":\"eth_chainId\"}\n \n Details: {\"code\":-32600,\"message\":\"The team owning this app is inactive. Please contact support at https://dashboard.alchemyapi.io/support\"}\n Version: [email protected]\n at Object.http (file:///home/node/app/node_modules/viem/utils/rpc.ts:116:13)\n at processTicksAndRejections (node:internal/process/task_queues:95:5)\n at fn (file:///home/node/app/node_modules/viem/clients/transports/http.ts:95:18)\n at request (file:///home/node/app/node_modules/viem/clients/transports/http.ts:97:39)\n at withRetry.delay.count.count (file:///home/node/app/node_modules/viem/utils/buildRequest.ts:69:18)\n at attemptRetry (file:///home/node/app/node_modules/viem/utils/promise/withRetry.ts:34:22) {\n details: '{\"code\":-32600,\"message\":\"The team owning this app is inactive. Please contact support at https://dashboard.alchemyapi.io/support\"}',\n docsPath: undefined,\n metaMessages: [\n 'Status: 403',\n 'URL: https://eth-mainnet.g.alchemy.com/v2/xxxxxxx',\n 'Request body: {\"method\":\"eth_chainId\"}'\n ],\n shortMessage: 'HTTP request failed.',\n version: '[email protected]',\n body: { method: 'eth_chainId', params: undefined },\n headers: Headers {\n date: 'Tue, 23 Jul 2024 06:08:42 GMT',\n 'content-type': 'application/json',\n 'transfer-encoding': 'chunked',\n connection: 'keep-alive',\n 'cf-ray': '8a797f576f658d7d-HEL',\n 'cf-cache-status': 'DYNAMIC',\n 'access-control-allow-origin': '*',\n 'access-control-allow-credentials': 'true',\n 'x-alchemy-trace-id': '566a1d39bfde62b5ad34b8992802247d',\n vary: 'Accept-Encoding',\n 'set-cookie': '_cfuvid=G2aIxEQkb0WFgGS5WwMWy6PfF.fv1tBYitHfkb6q95g-1721714922284-0.0.1.1-604800000; path=/; domain=.g.alchemy.com; HttpOnly; Secure; SameSite=None',\n server: 'cloudflare',\n 'content-encoding': 'gzip'\n },\n status: 403,\n url: 'https://eth-mainnet.g.alchemy.com/v2/vuV2Lnbm4S7IYGtfrM_sBEKnOYX62Yo0'\n }\n}\n","timestamp":"2024-07-23T06:08:42.295Z","type":"out","process_id":0,"app_name":"hubble"}似乎是最近 alchemy 做了什么调整,导致很早之前的 App URL 连接失效了。查看控制台日志可以看到都是失败的 reqeust:
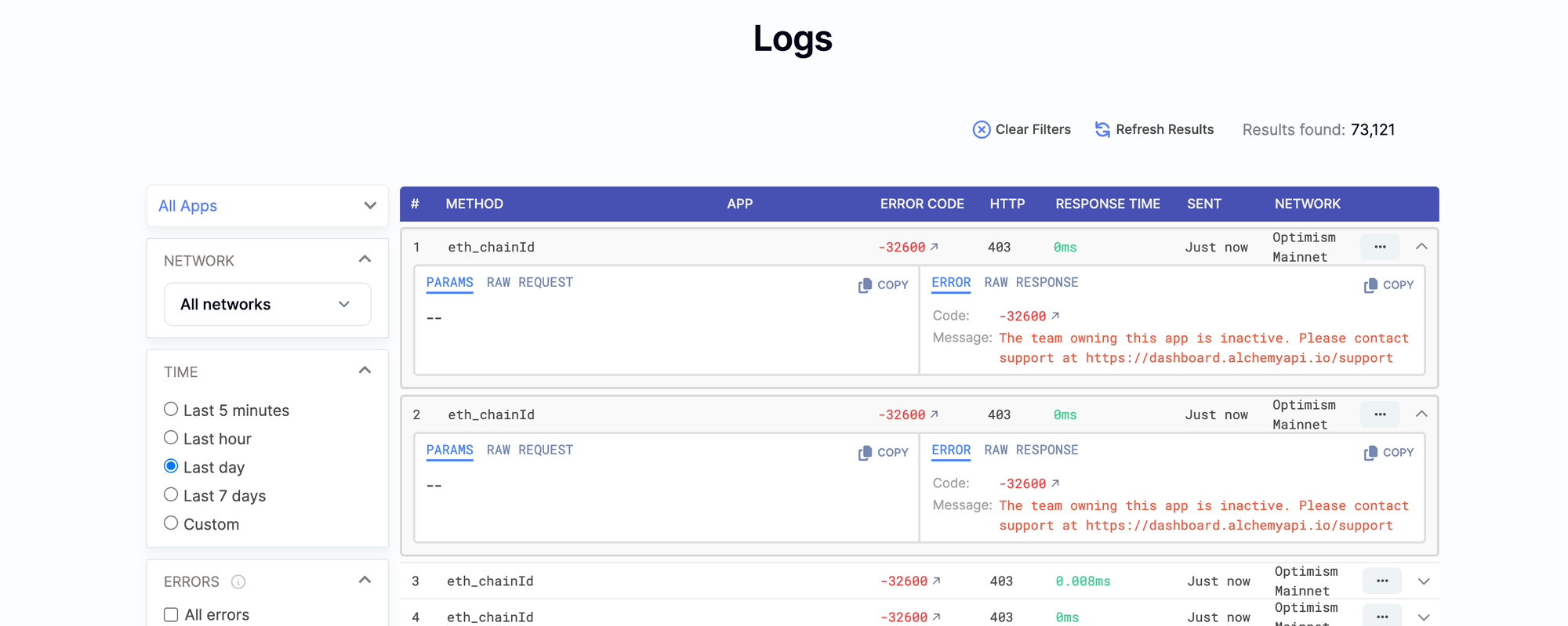
解决方法也很简单 直接使用 publicnode(可能相对慢和不稳定一些)替换掉 hubble 中的这两个参数:
ETH_MAINNET_RPC_URL=https://ethereum-rpc.publicnode.com
OPTIMISM_L2_RPC_URL=https://optimism-rpc.publicnode.com然后 docker compose up -d 重新启动即可。
以及在升级过程中我发现了很有意思的声明:
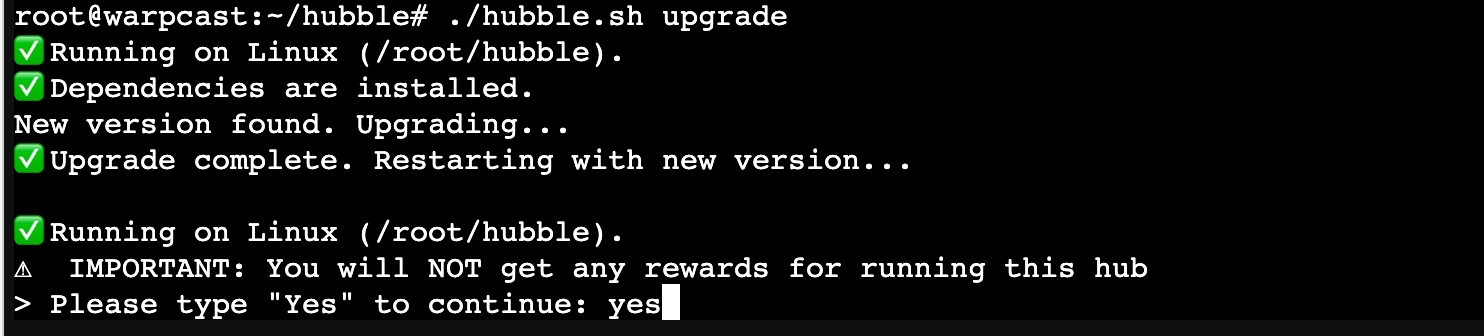
所以大概率是不会有任何回报啦。有机器的话就留着,没机器的话就删了回收了吧。
参考

![代币分析之 SUI [260202]](/content/images/size/w600/2026/02/Gemini_Generated_Image_zek2vjzek2vjzek2.png)

![股票研究之 RDW [260129]](/content/images/size/w600/2026/01/Gemini_Generated_Image_kgmv2wkgmv2wkgmv.png)
![代币研究之 XRP [260128]](/content/images/size/w600/2026/01/Gemini_Generated_Image_4naabk4naabk4naa.png)